RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 10 novembro 2024

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.

Johan Gras (@gras_johan) / X

Memory-based Reinforcement Learning
Kristian Kersting
Summaries from arXiv e-Print archive on
Tags
RL Weekly

RL Weekly 37: Observational Overfitting, Hindsight Credit Assignment, and Procedurally Generated Environment Suite
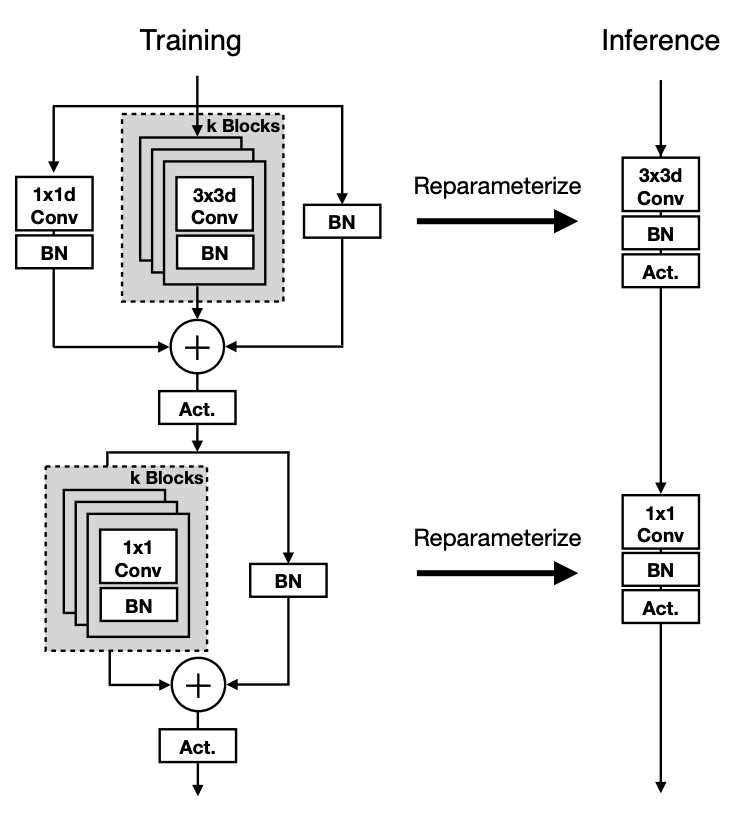
Aman's AI Journal • Papers List

Mastering Atari Games with Limited Data – arXiv Vanity

PDF) OCAtari: Object-Centric Atari 2600 Reinforcement Learning Environments

Memory for Lean Reinforcement Learning.pdf

deep learning – Severely Theoretical
RL Weekly 32: New SotA Sample Efficiency on Atari and an Analysis of the Benefits of Hierarchical RL
Recomendado para você
-
 AlphaZero on Carlsen-Caruana Games 1-810 novembro 2024
AlphaZero on Carlsen-Caruana Games 1-810 novembro 2024 -
 A New Kind Of Chess! - AlphaZero vs. Stockfish, 201710 novembro 2024
A New Kind Of Chess! - AlphaZero vs. Stockfish, 201710 novembro 2024 -
 Reimagining Chess with AlphaZero, February 202210 novembro 2024
Reimagining Chess with AlphaZero, February 202210 novembro 2024 -
 AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours10 novembro 2024
AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours10 novembro 2024 -
 Lessons from AlphaZero for Optimal, by Dimitri P. Bertsekas10 novembro 2024
Lessons from AlphaZero for Optimal, by Dimitri P. Bertsekas10 novembro 2024 -
How deep can an alpha zero chess think? - Quora10 novembro 2024
-
 AlphaZero AI beats champion chess program after teaching itself in10 novembro 2024
AlphaZero AI beats champion chess program after teaching itself in10 novembro 2024 -
 AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript10 novembro 2024
AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript10 novembro 2024 -
 From-scratch implementation of AlphaZero for Connect410 novembro 2024
From-scratch implementation of AlphaZero for Connect410 novembro 2024 -
 AlphaZero Is the New Chess Champion, and Harbinger of a Brave New World in AI10 novembro 2024
AlphaZero Is the New Chess Champion, and Harbinger of a Brave New World in AI10 novembro 2024
você pode gostar
-
 Finals, ROBLOX Camping Wiki10 novembro 2024
Finals, ROBLOX Camping Wiki10 novembro 2024 -
 Roblox Auto Clicker 🟥 Auto Clicker for Roblox (iOS/Android) in10 novembro 2024
Roblox Auto Clicker 🟥 Auto Clicker for Roblox (iOS/Android) in10 novembro 2024 -
Halo on Paramount+ - Vannak-134 is one of Silver Team's finest. #HaloTheSeries10 novembro 2024
-
 Star Fox (Japanese Import) : Video Games10 novembro 2024
Star Fox (Japanese Import) : Video Games10 novembro 2024 -
 PlayStation Plus adds Crash Bandicoot 4 and Man of Medan in July10 novembro 2024
PlayStation Plus adds Crash Bandicoot 4 and Man of Medan in July10 novembro 2024 -
 Baconhair 3D models - Sketchfab10 novembro 2024
Baconhair 3D models - Sketchfab10 novembro 2024 -
 YuYu Hakusho Botan Rainbow Foil Holo Character Art Card Figure Anime Manga10 novembro 2024
YuYu Hakusho Botan Rainbow Foil Holo Character Art Card Figure Anime Manga10 novembro 2024 -
 The Art of Ready Player One – Insight Editions10 novembro 2024
The Art of Ready Player One – Insight Editions10 novembro 2024 -
 SWAT Pack 810 novembro 2024
SWAT Pack 810 novembro 2024 -
Nova Top Criminal chegando! E muitas novidades da nova parceria do Fre10 novembro 2024

