Move over AlphaGo: AlphaZero taught itself to play three different games
Por um escritor misterioso
Last updated 19 setembro 2024
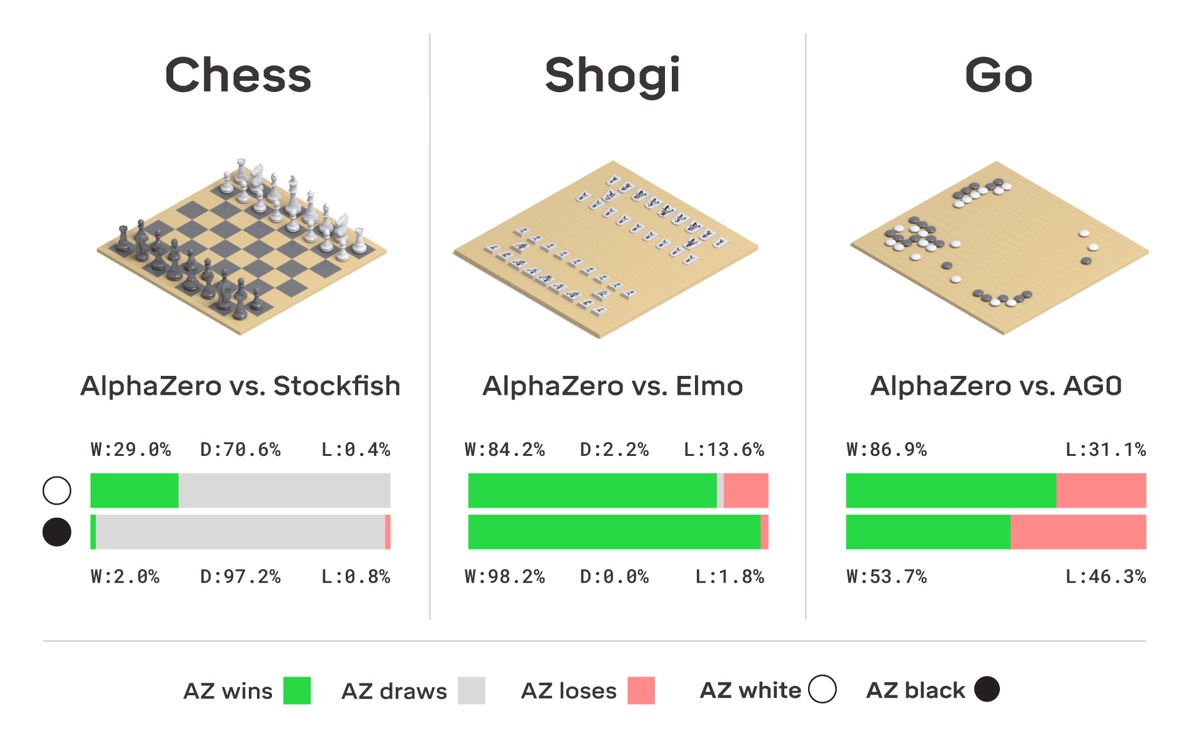
DeepMind's new AI is worthy successor to the first program to beat a human at Go.

Alphazero :: Computer-bridge1

Why DeepMind AlphaGo Zero is a game changer for AI research

Neural networks: The apocalypse is (almost) here

AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community

Building Our Own Version of AlphaGo Zero

How Does AlphaZero Play Chess?
What was the significance of move 37 and move 78 in Go? (AlphaGo versus Lee Sedol) - Quora

The AI That Has Nothing to Learn From Humans - The Atlantic

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Google's New AI Is a Master of Games, but How Does It Compare to the Human Mind?, Innovation

AlphaZero

New AlphaGo Zero Unsupervised AI is 100X Better While Using 10% Computing Power
Recomendado para você
-
 PLAY-CHESS-ALPHAZERO - Play Chess with Friends19 setembro 2024
PLAY-CHESS-ALPHAZERO - Play Chess with Friends19 setembro 2024 -
 AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours19 setembro 2024
AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours19 setembro 2024 -
 Chess-Network's Blog • Magnus Carlsen plays like AlphaZero19 setembro 2024
Chess-Network's Blog • Magnus Carlsen plays like AlphaZero19 setembro 2024 -
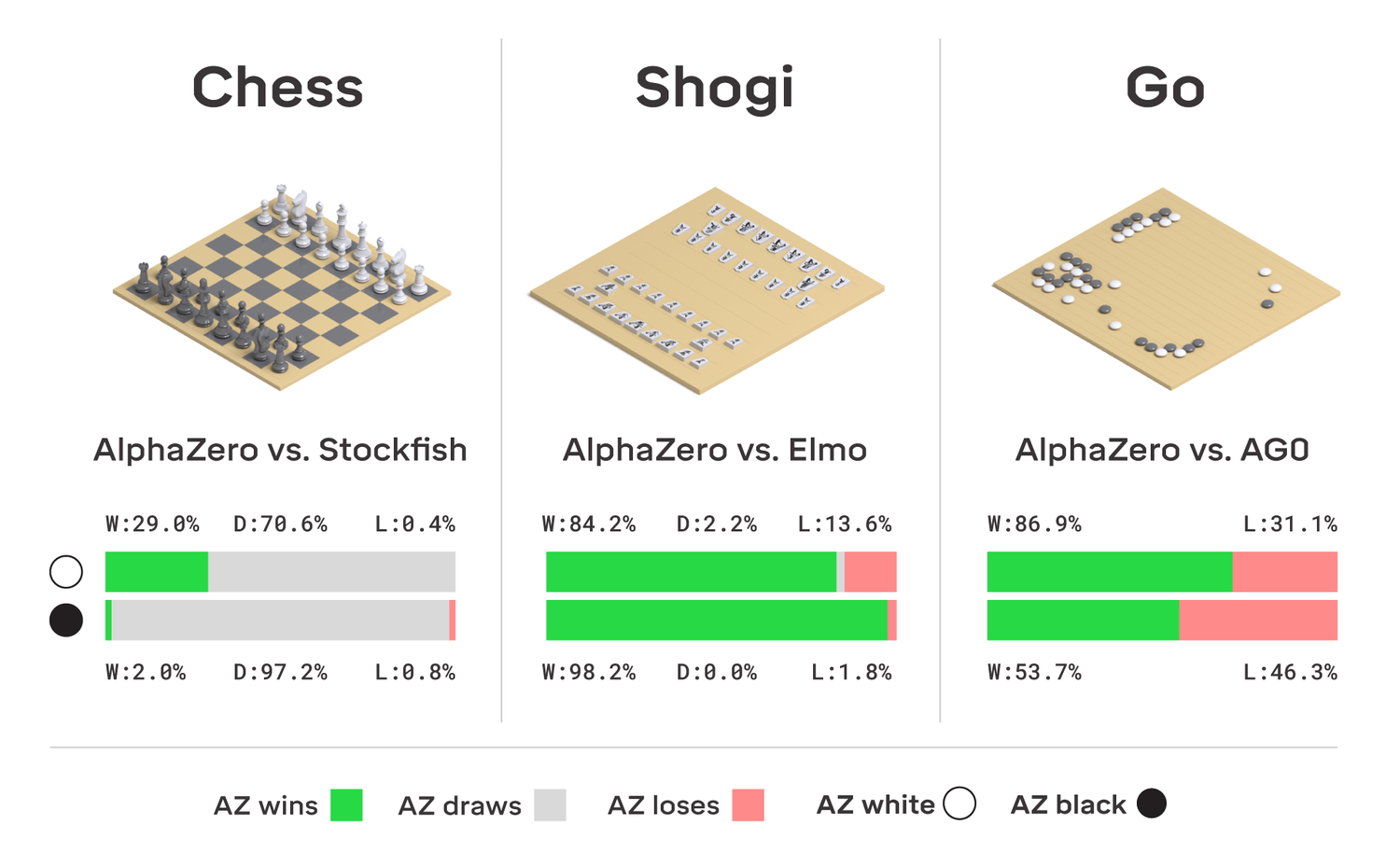 DeepMind's New AI Teaches Itself Chess, Beats Grandmaster19 setembro 2024
DeepMind's New AI Teaches Itself Chess, Beats Grandmaster19 setembro 2024 -
 AlphaZero vs Stockfish 8: A Landmark Battle of Human and Artificial Intelligence in Chess, by David Georgyan19 setembro 2024
AlphaZero vs Stockfish 8: A Landmark Battle of Human and Artificial Intelligence in Chess, by David Georgyan19 setembro 2024 -
 Google DeepMind Researchers Uncover the Power of AI Diversity in Tackling Chess Challenges: Introducing AZ_db, the Next Leap in Computational Problem-Solving - MarkTechPost19 setembro 2024
Google DeepMind Researchers Uncover the Power of AI Diversity in Tackling Chess Challenges: Introducing AZ_db, the Next Leap in Computational Problem-Solving - MarkTechPost19 setembro 2024 -
 Alphazero19 setembro 2024
Alphazero19 setembro 2024 -
Dispatches from the frontiers of chess19 setembro 2024
-
Is there an Open Source version of AlphaZero? (specifically, the generic game-learning tool, distinct from AlphaGo) - Quora19 setembro 2024
-
Understanding AlphaZero Neural Network's SuperHuman Chess Ability - MarkTechPost19 setembro 2024


você pode gostar
-
 All Garten of Banban Stories by Horror Skunx! (Jumbo Josh, Nabnab19 setembro 2024
All Garten of Banban Stories by Horror Skunx! (Jumbo Josh, Nabnab19 setembro 2024 -
 Super Mario Bros. O Filme: Seth Rogen responde críticas sobre voz19 setembro 2024
Super Mario Bros. O Filme: Seth Rogen responde críticas sobre voz19 setembro 2024 -
Today In Chess: Candidates Round 7 Recap19 setembro 2024
-
 vaughn ring party|TikTok Search19 setembro 2024
vaughn ring party|TikTok Search19 setembro 2024 -
 Blob FIsh - Imgflip19 setembro 2024
Blob FIsh - Imgflip19 setembro 2024 -
 Lugia & Ho-Oh Pokémon Pins (2-Pack)19 setembro 2024
Lugia & Ho-Oh Pokémon Pins (2-Pack)19 setembro 2024 -
 Jogo Dominó Clássico Madeira Pais e Filhos - Ri Happy19 setembro 2024
Jogo Dominó Clássico Madeira Pais e Filhos - Ri Happy19 setembro 2024 -
 Zootopia (2016) in 2023 Zootopia, Zootopia 2016, Walt disney animation studios19 setembro 2024
Zootopia (2016) in 2023 Zootopia, Zootopia 2016, Walt disney animation studios19 setembro 2024 -
![Qin Shi Huang vs Hades Rei vs Rei a Luta completa [Shuumatsu no Valkyrie]](https://i.ytimg.com/vi/Ts4clFcJfz8/maxresdefault.jpg) Qin Shi Huang vs Hades Rei vs Rei a Luta completa [Shuumatsu no Valkyrie]19 setembro 2024
Qin Shi Huang vs Hades Rei vs Rei a Luta completa [Shuumatsu no Valkyrie]19 setembro 2024 -
tr.rbxcdn.com/5087cd04a0ddd0208b4d3aabd558afa2/57619 setembro 2024

