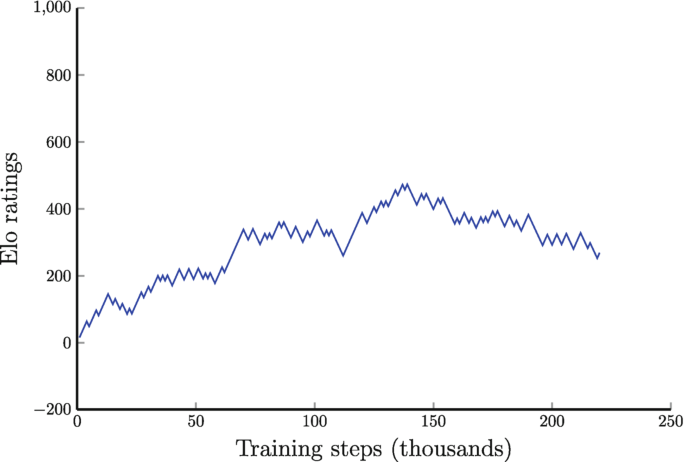
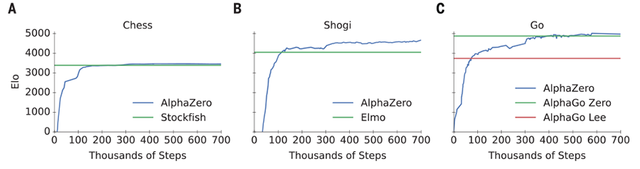
Training AlphaZero for 700,000 steps. Elo ratings were computed from
Por um escritor misterioso
Last updated 20 setembro 2024


Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm – arXiv Vanity

Generally capable agents emerge from open-ended play - Google DeepMind
Planning with a Model: AlphaZero

Figure 1 from Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Science Magazine - December 7, 2018 - A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

AlphaZero: Shedding new light on the grand games of chess, shogi and Go [DM releases followup paper on AlphaZero, +100 shogi games, +100 chess games, and video discussion] : r/reinforcementlearning

PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm – arXiv Vanity

DeepMind's AlphaZero beats state-of-the-art chess and shogi game engines

Checkmate for Traditional Chess? - Nekst-Online

From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning

Generally capable agents emerge from open-ended play - Google DeepMind
Recomendado para você
-
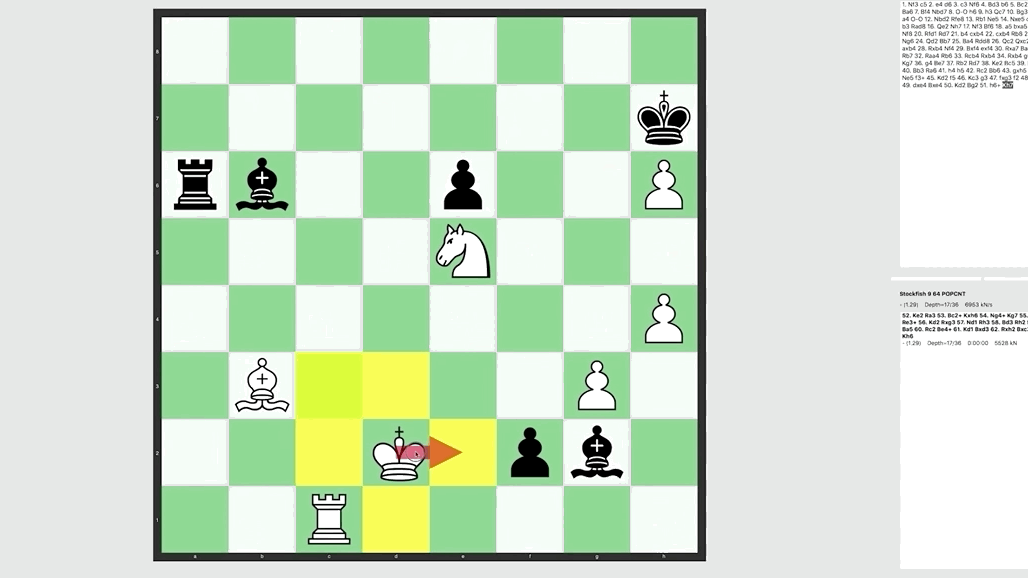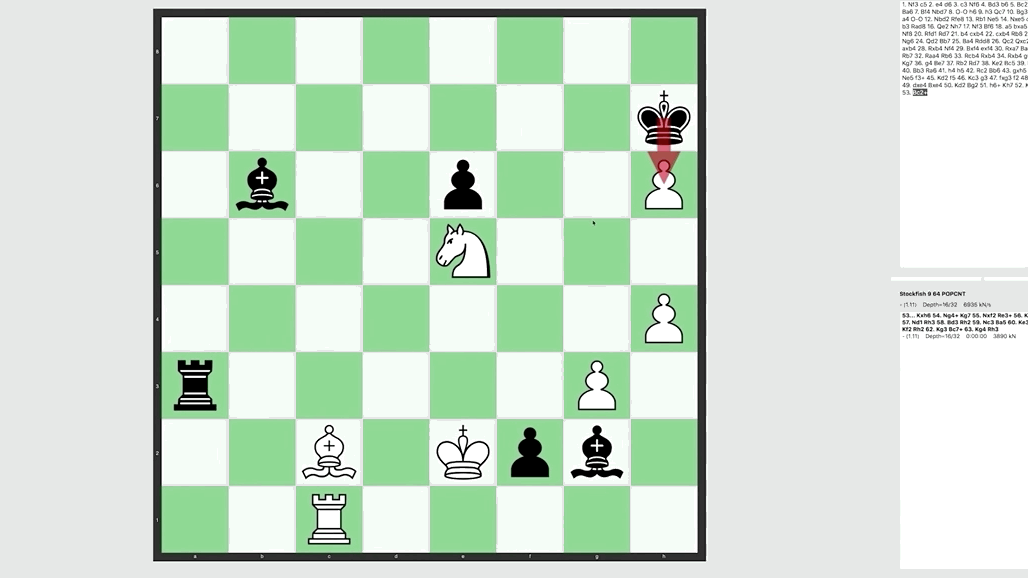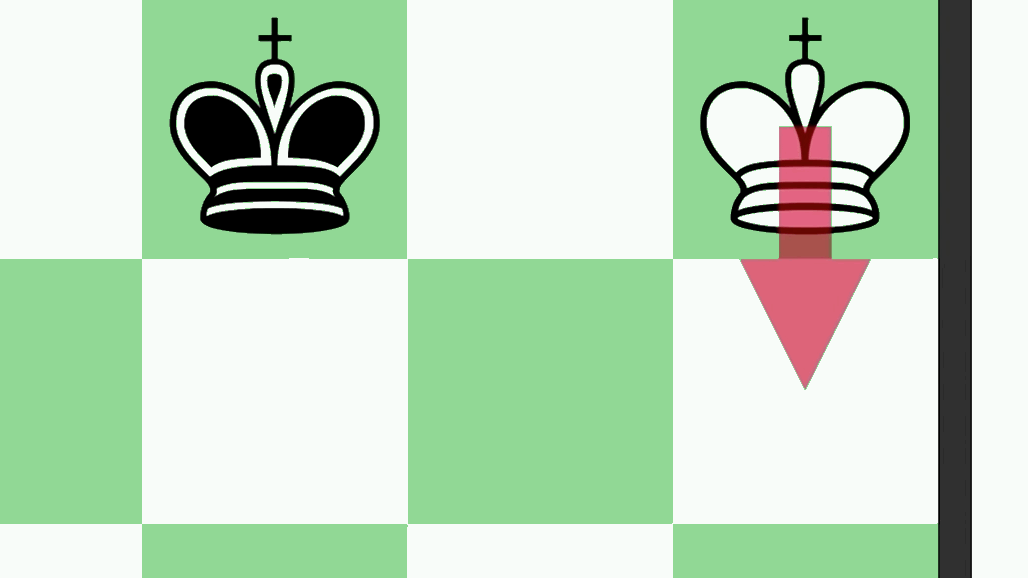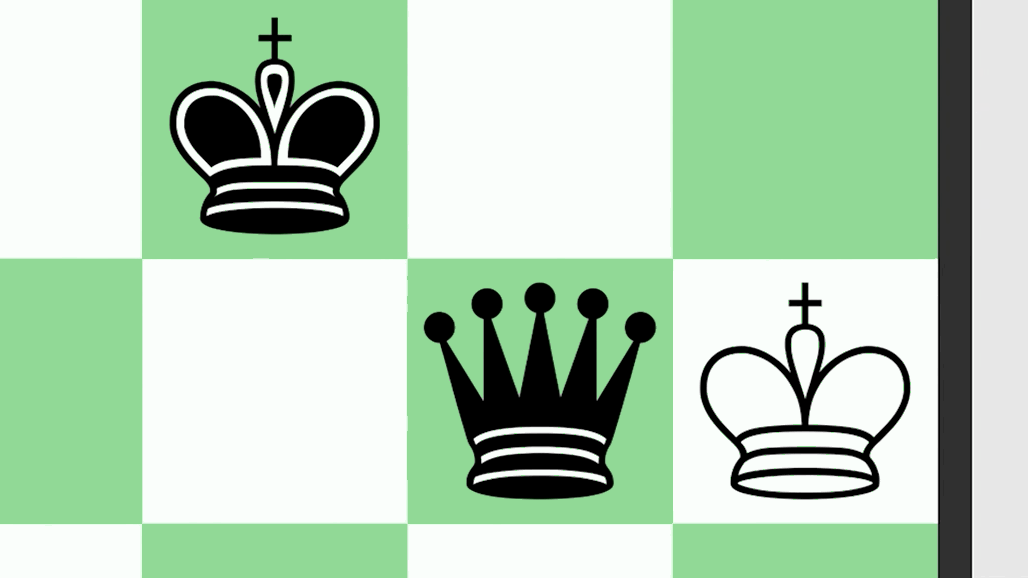 AlphaZero Vs. Stockfish 8 AI Is Conquering Computer Chess20 setembro 2024
AlphaZero Vs. Stockfish 8 AI Is Conquering Computer Chess20 setembro 2024 -
 AlphaZero, Vladimir Kramnik and reinventing chess20 setembro 2024
AlphaZero, Vladimir Kramnik and reinventing chess20 setembro 2024 -
 Leela Chess Zero: AlphaZero for the PC20 setembro 2024
Leela Chess Zero: AlphaZero for the PC20 setembro 2024 -
 Google's AlphaZero Destroys Stockfish In 100-Game Match20 setembro 2024
Google's AlphaZero Destroys Stockfish In 100-Game Match20 setembro 2024 -
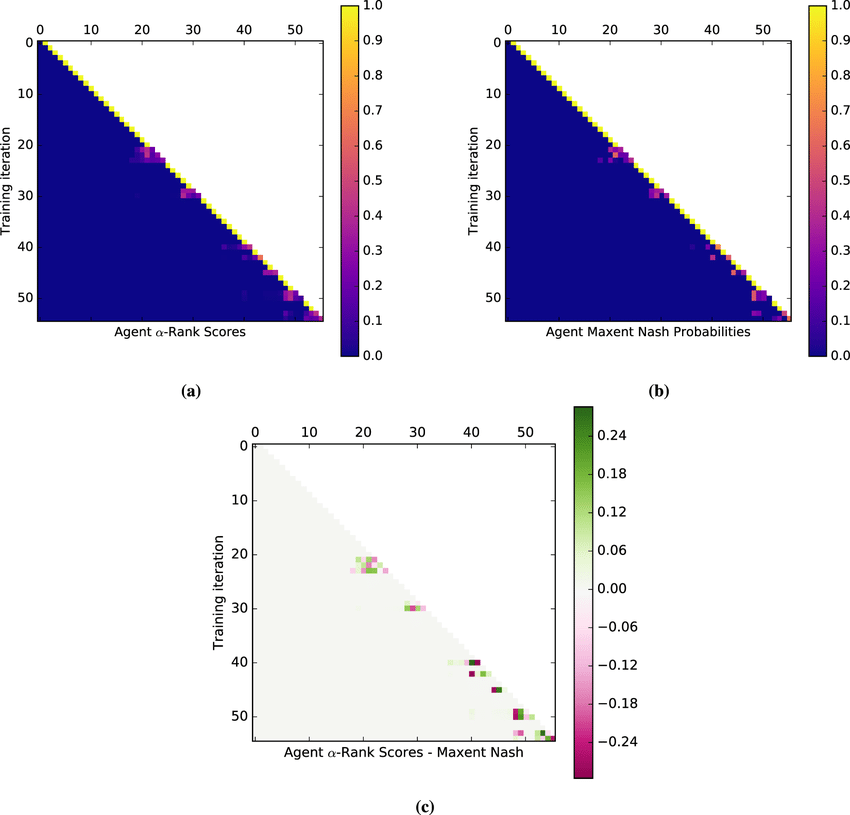 AlphaZero (chess) agent evaluations throughout training. (a) α-Score20 setembro 2024
AlphaZero (chess) agent evaluations throughout training. (a) α-Score20 setembro 2024 -
 The AlphaZero-FX network outperforms the vanilla version that uses20 setembro 2024
The AlphaZero-FX network outperforms the vanilla version that uses20 setembro 2024 -
 AlphaZero-Gomoku APK for Android Download20 setembro 2024
AlphaZero-Gomoku APK for Android Download20 setembro 2024 -
 ALPHA ZERO Songs MP3 Download, New Songs & Albums20 setembro 2024
ALPHA ZERO Songs MP3 Download, New Songs & Albums20 setembro 2024 -
 Alphazero PNG Images, Alphazero Clipart Free Download20 setembro 2024
Alphazero PNG Images, Alphazero Clipart Free Download20 setembro 2024 -
AlphaZero: Shedding new light on chess, shogi, and Go - Google DeepMind20 setembro 2024

você pode gostar
-
 Bitspower Nebula VGA Water Block For GALAX GeForce RTX 4080 HOF20 setembro 2024
Bitspower Nebula VGA Water Block For GALAX GeForce RTX 4080 HOF20 setembro 2024 -
 Legendary Pokémon Locations: Brilliant Diamond Shining Pearl20 setembro 2024
Legendary Pokémon Locations: Brilliant Diamond Shining Pearl20 setembro 2024 -
 Gop 500 Cards-inclui App-jogos De Beber-jogos De Beber Para Adultos Festa- jogo De Tabuleiro Para Adultos-jogos De Cartas Divertidos - Jogos De Tabuleiro - AliExpress20 setembro 2024
Gop 500 Cards-inclui App-jogos De Beber-jogos De Beber Para Adultos Festa- jogo De Tabuleiro Para Adultos-jogos De Cartas Divertidos - Jogos De Tabuleiro - AliExpress20 setembro 2024 -
 Angry Birds Epic - Download Tutorial v2.0 With Working Events20 setembro 2024
Angry Birds Epic - Download Tutorial v2.0 With Working Events20 setembro 2024 -
 Hshs Hdhdhd20 setembro 2024
Hshs Hdhdhd20 setembro 2024 -
 Outfit Ideas Gacha For Life for Android - Download20 setembro 2024
Outfit Ideas Gacha For Life for Android - Download20 setembro 2024 -
/i.s3.glbimg.com/v1/AUTH_59edd422c0c84a879bd37670ae4f538a/internal_photos/bs/2022/c/7/OgbunwSnytvxKKj5BCTA/guincho.jpg) Carro infantil motorizado pode transitar na rua? Entenda as regras20 setembro 2024
Carro infantil motorizado pode transitar na rua? Entenda as regras20 setembro 2024 -
 Media Markt - Simple English Wikipedia, the free encyclopedia20 setembro 2024
Media Markt - Simple English Wikipedia, the free encyclopedia20 setembro 2024 -
Fallout 3 Xbox One — buy online and track price history — XB Deals Norge20 setembro 2024
-
 Chainsaw Man provou que sucesso no Brasil não foi à toa ao ganhar o Harvey Awards20 setembro 2024
Chainsaw Man provou que sucesso no Brasil não foi à toa ao ganhar o Harvey Awards20 setembro 2024
